Introduction
In Fall 2013, we rolled out some significant improvements for Chinese, Japanese and Korean (CJK) resource discovery in SearchWorks, the Stanford library "catalog" built with Blacklight on top of our Solr index. If your collection has a significant number of CJK resources and they are in multiple languages, you might be interested in our recipes. You might also be interested if you have a significant number of resources in multiple languages, period.If you are interested in improving searching, or in improving your methodology when working on searching, these posts provide a great deal of information. Analysis of Solr result relevancy figured heavily in this work, as did testing: relevancy/acceptance/regression testing against a live Solr index, unit testing, and integration testing. In addition, there was testing by humans, which was well managed and produced searches that were turned into automated tests. Many of the blog entries contain useful approaches for debugging Solr relevancy and for test driven development (TDD) of new search behavior.
Resource Discovery with CJK Improvements
The production discovery service for the Stanford University Libraries is SearchWorks, which has all the CJK improvements discussed in the previous twelve blog posts: http://searchworks.stanford.eduWhere's the Code?
- https://github.com/solrmarc/stanford-solr-marc - Stanford's fork of SolrMarc (for indexing our Marc data into Solr)
- stanford-sw/solr - Solr config files, jars, etc.
- https://github.com/sul-dlss/sw_index_tests - over 1000 relevancy tests run against our production Solr index
- spec/cjk - tests for CJK
- https://github.com/solrmarc/CJKFoldingFilter - a Solr filter to get better recall for Chinese and Japanese when using solr.ICUTransformFilter translation from traditional Han/Kanji characters to simplified/modern Han/Kanji characters.
- SearchWorks application code - currently available upon request (will be on github in the next few months). This is a Ruby on Rails application built with Blacklight.
- Blacklight - a configurable Ruby on Rails front-end to provide a discovery UI for a Solr index.
- Solr - a search platform available from the Apache Lucene project.
CJK Work
CJK Overview
Why do we care about CJK resource discovery? (part 1)Why approach CJK resource discovery differently? (part 1)
Our CJK Discovery Priorities (part 1)
CJK Data
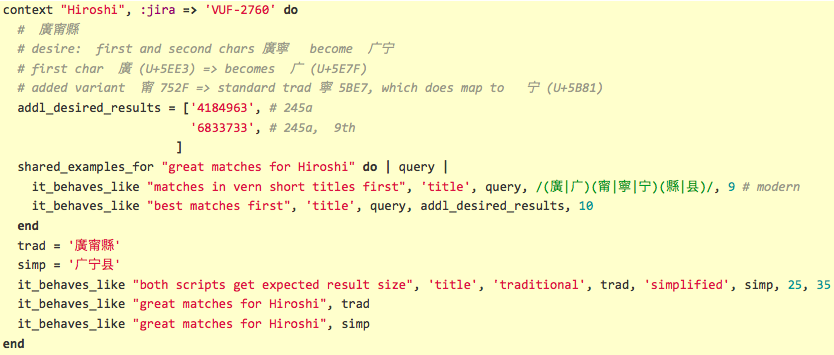
Where is our CJK data in our MARC records? (part 7)Extraneous spaces in CJK MARC data (part 11)
number of characters in CJK queries (part 8)
Solutions Made Available with Solr
Solr Language Specific Analysis (part 2)Multilingual CJK Solutions (part 2)
Solr CJK Script Translations (part 2)
ICUFoldingFilter (part 7)
CJKBigramFilter (part 2)
CJKBigramFilter prerequisites (part 2 (edismax); part 7 (tokenizer))
Our Specific CJK Solutions for Solr
text_cjk Solr fieldtype definition (part 7, part 10, part 11)mm for CJK (part 8, part 12)
phrase searching: qs for CJK (part 9)
catch-all field (part 9)
special non-alpha chars vs. cjk (part 10)
CJKFoldingFilter for variant Han/Kanji characters (part 11)
Remove extraneous spaces in Korean MARC data (part 11)
CJK relevancy tests (part 8, part 9, part 10, part 11, part 12)
Discovery UI Application Changes
applying LocalParams on the fly (part 10)detecting CJK in a query string (part 10)
additional quotation mark characters (part 12)
CJK advanced search (part 12)
Solr in General
Field Analysis
anchored text fieldtype (exactish match) (part 6)anchored text and synonyms (part 6)
removing trailing punctuation with a patternReplaceCharFilterFactory (part 6)
LocalParams (part 10)
solrconfig file variables with LocalParams (part 10)
patternReplaceCharFilterFactory (part 11, part 6)
ICUTokenizer (part 7)
Unicode normalization via ICUFoldingFilterFactory (part 7)
ICUTransformFilterFactory (part 2, part 7)
synonyms (part 6)
positionIncrementGap (part 7)
autoGeneratePhraseQueries (part 7)
Debugging Relevancy
how to analyze relevancy problems (part 3, part 4, part 5, part 6, part 9, part 10)debug argument (part 3)
analysis GUI (part 3)
relevancy score (part 3)
score visualization via http://solr.pl/en/ (part 3, part 5)
Edismax Issues
(part 3, part 4, part 5)relevancy formula change (part 5)
relevancy workaround: anchored text fieldtype (exactish match) (part 6)
tie parameter (part 5)
boolean operators bug (and other bugs) (part 4)
split tokens bug SOLR-3589 (part 2)
Testing
first pass human testing of CJK (part 8)broader human testing of CJK (part 9)
Relevancy/Acceptance/Regression Testing
overview (part 3)approach for high level view of search result quality (part 9)
specific relevancy tests (part 8, part 9, part 10, part 11, part 12)
detecting CJK in a query string (part 10)
Data Based Decisions
is Boolean syntax utilized in actual user queries? (part 4)workaround for edismax relevancy change (part 6)
what should CJK mm value be? (part 8)