The last three posts were focused on diagnosing and mitigating the differences between the edismax and dismax query parsers, since edismax (and Solr release of 4.1 or later) is a prerequisite for a critical bug fix for CJK analysis. Note that without this bug fix, one of our CJK experts referred to the search results we were getting as "inexplicable."
As a refresher, we recall our original mission from the first blog post in this series:
CJK Discovery Priorities
Chinese
- Equate Traditional Characters With Simplified Characters
- Word Breaks
Japanese
- Equate Traditional Kanji Characters With Modern Kanji Characters
- Equate All Scripts
- Imported Words
- Word Breaks
Korean
- Word Breaks
- Equate Hangul and Hancha Scripts
Solr Solutions to Leverage
We borrow from the second post in this series to remind ourselves which Solr tools interest us for our Solr CJK processing needs:
1. CJKBigram Analysis
Tom Burton-West's blog post advises the use of a combination of overlapping bigrams and unigrams of CJK characters for multilingual discovery. The CJKBigramFilter, new with Solr 3.6, allows us to generate both the unigrams and the bigrams for CJK scripts only: perfect.
In the future, Solr may provide CJK dictionary-based segmentation (see LUCENE-4381 and SOLR-4123), but it doesn't exist yet. The ability to provide your own rules for tokenizing has arrived, though! See the javadoc for the ICUTokenizerFactory for more information.
An important note: The CJKBigramFilter must be fed appropriate values for the token type. This can be learned from the source code:

a. ICUTokenizer
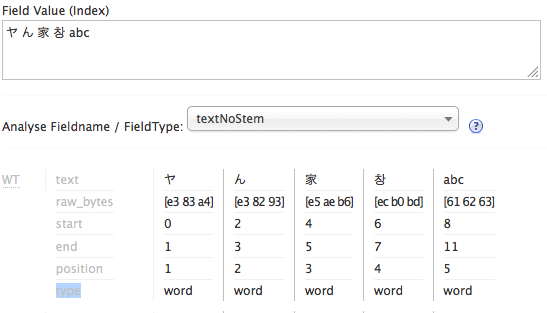
Here is output from Solr admin analysis on a string with four different CJK scripts as well as latin. Note the type attribute, which I highlighted in the label column on the left:

b. StandardTokenizer
Note that the StandardTokenizer output does not separate the Hangul character from the Latin characters at the end.

I believe ClassicTokenizer will also assign token types, probably the same way StandardTokenizer does.
The WhitespaceTokenizer is an example of a Tokenizer that does not assign the types. I have added spaces to the string to emphasize the difference in the token types assigned:
2. ICU Script Translations
Solr makes the following script translations available via the solr.ICUTransformFilterFactory:- Han Traditional <--> Simplified
- Katakana <--> Hiragana
3. ICU Folding Filter
We have already been using solr.ICUFoldingFilterFactory for case folding, e.g. normalizing "A" to "a." Even though CJK characters don't have the concept of upper and lower case, many CJK and other Unicode characters can be expressed multiple ways by using different code point sequences. The ICUFoldingFilter uses NFKC Unicode normalization, which does a compatibility decomposition (using a broader, "compatible" notion of character equivalence and "decomposing" to distinct code points to represent separate-able parts of a character) followed by a canonical composition (the narrower, "canonical" notion of equivalence, and the more compact code point representation of characters). We experimented with different flavors of Unicode normalization and found NFKC to be just fine for CJK discovery purposes. I may talk about this further in a later post.Solr Fieldtype Definition
The example schema provided with Solr shows one way you might configure a fieldtype to do CJKBigramming:
So our improved version of the above might look like this:

Let's examine it more closely:
- positionIncrementGap attribute on fieldType
- autoGeneratePhraseQueries attribute on fieldType As LUCENE-2458 describes, prior to Solr 3.1, if more than one token was created for whitespace delimited text, then a phrase query was automatically generated. While this behavior is generally desired for European languages, it is not desired for CJK. Oddly, when this bug was fixed and a configuration setting was made available, they changed the default behavior - the default is now false. "false" is the correct value for CJK, while "true" is most likely what you want in other contexts. The Jira ticket description is pretty readable; Tom Burton-West also mentions this in his blog, and I briefly talk about it in my blog entry about upgrading from Solr 1.4 to Solr 3.5.
- ICUTokenizerFactory The section above on CJKBigram analysis shows that the ICUTokenizer is likely to be better than the StandardTokenizer for tokenizing CJK characters into typed unigrams, as needed by the CJKBigramFilter.
- CJKWidthFilterFactory It may be that this is completely unnecessary, but on the off chance that the script translations don't accommodate half-width characters, I go ahead and normalize them here. For the curious, written CJK characters can be very opaque, so old printers used to print each CJK character twice as wide as a Latin characters. However, some of the simpler characters could be printed regular size, or "half-width" compared to other CJK characters. (http://en.wikipedia.org/wiki/Halfwidth_and_fullwidth_forms)
- ICUTransformFilterFactory from Han traditional to simplified This is the translation of traditional Han characters to simplified Han characters, which will allow a query to match both traditional and simplified Han characters.
- ICUTransformFilterFactory from Katakana to Hiragana This is the translation of Katakana characters to Hiragana characters, which will allow both of these scripts to be matched when there are characters in either script in the user query.
- ICUFoldingFilterFactory This will perform Unicode normalization as described in the Solr solutions section above.
- CJKBigramFilterFactory Note the settings to bigram all four CJK scripts, and to output unigrams in addition to bigrams.
Our next step is to index all of our CJK data using this fieldtype, and then to include the new CJK fields in the boosted field lists searched by our edismax request handlers.
Where is our CJK Data?
In our preliminary testing, we confirmed SOLR-3589 made our CJK search results "inexplicable" (recall that this bug being fixed only for edismax is what drove us to switch to edismax). One way we assessed our results was by comparing them to search results in our traditional library OPAC (Symphony ILS by Sirsi if you're curious). For some of the very small result sets (15 hits or less), we could examine why each result was included by Solr and by the ILS. These close examinations surfaced CJK characters that weren't in the appropriate Marc linked data 880 fields, but instead were included in Marc fields 505 and 520. Many of these records came from external vendors. We then asked our East Asia librarians to estimate how often CJK scripts would occur outside 880s, and the guesses were about 30% of the Chinese records, 15% of the Korean records, and 5% of the Japanese records. With this in mind, we decided to apply the text_cjk fieldtype to 505 and 520 fields in addition to 880 fields.Our CJK Solr fields are all copy fields (more on that in a subsequent post); here are the relevant bits from our Solr schema.xml file, in addition to the fieldtype definition for text_cjk:


Note that the dynamicField declaration has indexed=true and stored=false: the display of CJK text in the SearchWorks application is accommodated via other fields. This whole effort is about CJK searching. CJK search fields must be multivalued because many of the relevant Marc fields are repeatable.
No comments:
Post a Comment