Let's recall the list of blocker, must do, and should do problems that cropped up with level 2 evaluation of CJK discovery in part nine (after relevancy tweaks for edismax applied per part six, Solr fieldtype for text_cjk defined in part seven):
Blockers:
- other production behaviors broken (fix described in part ten)
- CJK phrase searching broken (fix described as CJK Tweak 2 in part nine)
- CJK author + title searches broken (fix described as CJK Tweak 3 in part nine)
- CJK advanced search broken
- cope with extra spaces in our CJK data
- additional "variant" Han/Kanji characters translated to simplified Han/Kanji characters
- accommodate variant quote marks
- beef up our CJK test suite (see https://github.com/sul-dlss/sw_index_tests/tree/master/spec/cjk)
- publish CJK solutions for others to use (that's these blog posts ...)
Extraneous Spaces in Marc CJK Metadata
As I stated in the first post of this series, cataloging practice for Korean for many years was to insert spaces between characters according to "word division" cataloging rules (See http://www.loc.gov/catdir/cpso/romanization/korean.pdf, starting page 16.) End-user queries would not use these spaces. It 's analog ous to spac ing rule s in catalog ing be ing like this for English.My trusty Stanford-Marc-Institutional-Memory guy, Vitus Tang, assured me there had been no practice, at least for us, to introduce extra whitespace into our Chinese or Japanese data. Only Korean got the benefit of this ... er ... interesting ... approach. Here's an example of a record with extra spaces in its title (which I have emphasized with red):

Here's the particular 880 field with the four spaces in the linked 245a (also emphasized with red):


According to our Korean librarians, users would most likely put no spaces in this query. They would next most likely put a single space between 이 and 될, or possibly a space between 이 and 될 as well as between 때 and 까.
Our full specs for Korean spacing issues are here: https://github.com/sul-dlss/sw_index_tests/blob/master/spec/cjk/korean_spacing_spec.rb.
Why are these extra spaces a problem? Think of it this way: for every space added, a potential bigram is removed. For 7 characters, we have 6 overlapping bigrams + 7 unigrams for 13 possible tokens. If we add a space, we have 5 bigrams + 7 unigrams for 12 tokens. If we add 4 total spaces, as in the record above, we have only 2 bigrams and 7 unigrams for 9 tokens. If the query is 7 characters with no spaces, and mm = 86% (as shown in part eight), we need 10 matching tokens. If we need 10 matching tokens, but there are only 9 tokens in the record itself, it will never match.
Vitus Tang had a great idea for addressing the information retrieval problems introduced by these extra spaces: what if we indexed the Korean text as if it didn't have spaces?
CJK Tweak 4: removing extraneous Korean spaces
Removing spaces from a string before analyzing it was a perfect case for a pre-tokenization character filter, PatternReplaceCharFilter. This is a tricky regex because it requires lookahead - you have to go past the space to see if it should be removed. To make it easier to follow, for now we will refer to a Korean character as \k and whitespace is \s, per usual regex predefined character classes. The lookahead construct is (?=X), so we get:\k*\s+(?=\k)
to remove any whitespace between Korean characters.Sadly, though, Korean characters can be Hangul script, which is only used by Korean, or they can be Han script, which is used by Chinese, Japanese and Korean. And Korean strings can have a mix of Hangul and Han characters (and Arabic numerals, as shown above). We can only know for certain we have Korean text if we encounter at least one Hangul character in the string. Using Unicode script names as character classes, per java 7, we can express \k as
[\p{Hangul}\p{Han}]
but to guarantee a Korean phrase, we must insist on at least one Hangul character. If we require a Hangul character at the beginning of a string, the lookahead expression to eliminate internal whitespace becomes:(\p{Hangul}\p{Han}*)\s+(?=[\p{Hangul}\p{Han}])If we require a Hangul character at the end of a string, the lookahead expression to eliminate internal whitespace becomes:
([\p{Hangul}\p{Han}])\s+(?=[\p{Han}\s]*\p{Hangul})This was non-obvious, but our tests for both Korean and Chinese helped us know when we got it wrong, and a regex tester (we used Rubular) helped us get the lookahead correct. Thanks go to Jon Deering for helping me with this. The charFilters, which go before the tokenizer in the analysis chain, look like this:

\p{Hangul}
becomes [\p{InHangul_Jamo}\p{InHangul_Compatibility_Jamo}\p{InHangul_Syllables}]
and \p{Han}
becomes the awful (reformatted for readability)
When we put these charFilters in the analysis chain, like so

the Korean spacing specs passed. W00t!
Variant Han Characters
As I've mentioned before, the ICU transform provided by Solr for traditional Han characters to simplified Han characters is incomplete. Some Japanese modern Kanji characters are not included in the transform, so Japanese search results for these modern Kanji characters won't include the corresponding traditional Kanji character. The following feedback gives an example:
A corresponding relevancy test might be:

Similarly, there are Chinese Unicode variants of traditional characters in our data (and in user queries):

The corresponding relevancy test might be:
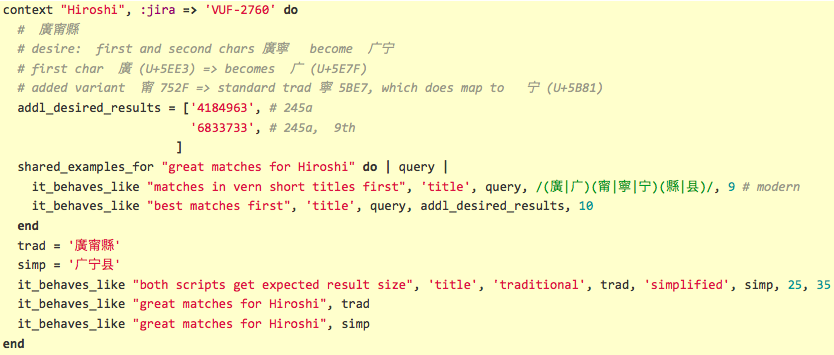
So we want to improve recall by adding some characters to the ICU transform from traditional Han to simplified Han. However, at the time, Solr only worked with the ICU System transforms. I didn't see an easy way to alter the ICU transform, but knew I could write a Solr filter that I could add to the analysis chain to accomplish our goal.
The specs for which characters to include came from our East Asia librarians. Most of the source characters are from Japanese modern Kanji, but there are also some Chinese traditional Han variant characters not covered by the ICU transform. This approach was made far less daunting when I told the librarians that we could add in more characters at any time -- they didn't need to provide me with a comprehensive list from the get-go.
One note: for a CJK-illiterate such as myself, the pattern recognition on similar CJK characters is not great, especially for traditional Han script characters. It was really helpful when the Unicode codepoint was provided, in addition to the character in question. I ended up doing a lot of web lookups of codepoint to character and vice versa.
CJK Tweak 5: CJKFoldingFilter
The same wonderful folks at http://solr.pl who created the pie chart visualization of Solr scores have two blog posts on writing Solr filters. Their first post is about writing one for Solr 3.6; their second post is for Solr 4.1. By the time I was implementing this, we were at Solr 4.4, but I found both posts useful, as well as various other sources I bumped into via Google.Conceptually, what we want this filter to do is very simple: when ever it encounters characters with particular Unicode codepoints, substitute different Unicode characters, such that the end result is that the original character, when passed through our entire analysis chain, will match the equivalent (simplified Han/modern Kanji) character. The code for this Solr filter, complete with test code, jars for testing, and ant build scripts, is at https://github.com/solrmarc/CJKFoldingFilter.
The source code itself is very small. We need a factory class that extends org.apache.lucene.analysis.util.TokenFilterFactory:


Note that I deliberately wrote the tests with a different notation, to hopefully catch any transcription errors:

In addition to various jars needed for testing, I found I needed some additional testing code to get my tests to work. I figured this out by modeling my tests on what was in core code, and having the compile or execution output indicate what was missing. All the additional teseting code is in test/src/org/apache/lucene/analysis/util/BaseTokenStreamFactoryTestCase.java, which I shamelessly copied from the Lucene 4.4.0 analysis/common/src/test folder. The code I copied even has these cryptic comments:

Presumably this oddity has been addressed in a later release of Solr.
In any case, the CJKFoldingFilter I wrote passes all its tests, and when the CJKFolderFilter jar file is added to the Solr lib directory (the same place where all the icu jars go), and the filter is added to our fieldtype analysis chain:

all our Japanese and Chinese variant character tests pass.
It is crucial to note that CJKFoldingFilter must be added to the analysis chain BEFORE the ICUTransform from Traditional Han to Simplified Han.
You may have also noticed that this is the final version of the text_cjk fieldtype definition - it is what we are currently using for production SearchWorks.
No comments:
Post a Comment